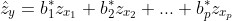A multiple regression model has more than one explanatory variable and sometimes also (a) controle variable(s): E(y) = α + β1x1 + β2x2. The explanatory variables are numbered: x1, x2, etc. When an explanatory variable is added, then the equation is extended with β2x2. The parameters are α, β1 and β2. The y-axis is vertical, x1 is horizontal and x2 is perpendicular to x1. In this three-dimensional graph the multiple regression equation describes a flat surface, called a plane.
A partial regression equation describes only part of the possible observations, only those with a certain value.
In multiple regression a coefficient indicates the effect of an explanatory variable on a response variable, while controlling for other variables. Bivariate regression completely ignores the other variables, multiple regression only brushes them aside for a bit. This is the basic difference between bivariate and multiple regression. The coefficient (like β1) of a predictor (like x1) tells what is the change in the mean of y when the predictor is raised by one point, controlling for the other variables (like x2). In that case, β1 is a partial regression coefficient. The parameter α is the mean of y when all explanatory variables are 0.
The multiple regression model has its limitations. An association doesn't automatically mean that there is a causal relationship, there may be other factors. Some researchers are more careful and call statistical control 'adjustment'. The regular multiple regression model assumes that there is no statistical interaction and that the slope β doesn't depend on which combination of explanatory variables is formed.
Multiple regression that exists in the population is estimated by the prediction equation : ŷ = a + b1 x1 + b2 x2 + … + b p x p in which p is the number of explanatory variables.
Just like the bivariate model, the multiple regression model uses residuals to measure prediction errors. For a predicted response ŷ and a measured response y, the residual is the difference between them: y – ŷ. The SSE (Sum of Squared Errors/Residual Sum of Squares) is similar as for bivariate models: SSE = Σ (y – ŷ)2, the only difference is the fact that the estimate ŷ is shaped by multiple explanatory variables. Multivariate models also use the least squares line, with the smallest possible SSE (which indicates how good or bad ŷ is in estimating y).
To check for linearity, multiple regression is plotted in a scatterplot matrix, a mosaic with scatterplots of the data points of several pairs of variables. Another option is to mark the different pairs in a single scatterplot. Software can create a partial regression plot, also called added-variable plot. This graph compares the residuals of different pairs and shows the relationship between the response variable and the explanatory variable after removing the effects of the other predictors.
For multiple regression, the sample multiple correlation, R, is the correlation between the observed and predicted y-values. R is between 0 and 1. When the correlation increases, so does the strength of the association between y and the explanatory variables. Its square, the multiple coefficient of determination, R2, measures the proportion of the variance in y that is explained by the predictive power of all explanatory variables. It has elements similar to the bivariate coefficient of determination:
Rule 1: y is predicted no matter what xp is. Then the best prediction is the sample mean ȳ.
Rule 2: y is predicted by xp. The prediction equation ŷ = a + b1x1 + b2x2 + … + bpxp predicts y.
The multiple coefficient of determination is the proportional limit of the number of errors: R2 = (TSS – SSE) / TSS in which TSS = Σ (y – ȳ)2 and SSE = Σ (y – ŷ)2.
Software like SPSS shows the output in an ANOVA table. The TSS is listed behind Total, under Sum of Squares and the SSE behind Residual, under Sum of Squares.
Characteristics of R-squared are:
R2 is between 0 and 1.
When SSE = 0, then R2 = 1 and the predictions are perfect.
When b1, b2, …, bp = 0 then R2 = 0.
When R2 increases, the explanatory variables predict y better.
R2 can't decrease when explanatory variables are added.
R2 is at least as big as the r2-values for the separate bivariate models.
R2 usually overestimates the population value, so software also offers an adjusted R2.
In case there are already a lot of strongly correlated explanatory variables, then R² changes little for adding another explanatory variable. This is called multicollinearity. Problems with multicollinearity are smaller for larger samples. Ideally the sample is at least ten times the size of the number of explanatory variables.
Significance tests for multiple regression can either check whether the collective of explanatory variables is related to y, or check whether the individual explanatory variables significantly effect y. In a collective significance test H0 : β1 = β2 = … = βp = 0 and Ha : (at least one of) βi ≠ 0 (i means any). This test measures whether the multiple correlation of the population is 0 or something else. The F-distribution is used for this significance test, resulting in the test statistic F:
&space;/&space;[n&space;-&space;(p+1)]})
In this p is the number of predictors (explanatory variables). The F-distribution only has positive values, is skewed to the right and averages at 1. The bigger R², the bigger F and the bigger the evidence against H0.
The F-distribution depends on two kinds of degrees of freedom: df1 = p (the number of predictors) and df2 = n – (p + 1). SPSS indicates F separately in the ANOVA table and P under Sig. (in R under p-value, in Stata under Prob > F and in SAS under Pr > F).
A significance test whether an individual explanatory variable (xi) has a partial effect on y, tests whether H0 : β i = 0 or Ha : βi ≠ 0. The confidence interval for βi is bi ± t(se) in which t = bi / se. In case of multicollinearity the separate P-values may not indicate correlations, while a collective significance test would clearly indicate a correlation.
For controlled explanatory variables, the conditional standard deviation is estimated by:

Software also calculates the conditional variance, called the error mean square (MSE) or residual mean square.
An alternative calculation for F uses the mean squares from the ANOVA table in SPSS. Then F = regression mean square / MSE in which regression mean square = regression sum of squares (in SPSS) / df1.
The t-distribution and the F-distribution are related, but F lacks information about the direction of an association and F is not appropriate for onesided alternative hypothesis.
Statistical interaction often happens in multiple regression: the interaction between x1 and x2 and their effect on y when the actual effect of x1 on y changes for different x2-values. A model using cross-product terms shows this interaction: E(y) = α + β1x1 + β2x2 + β3x1x2. A significance test with a null hypothesis H0 : β3 = 0 shows whether there is interaction. For little interaction, the cross-product term is better left out. For much interaction, it doesn't make sense anymore to do significance test for the other explanatory variables.
Coefficients often have limited use because they only indicate the effect of a variable when the other variables are constant. Coefficients become more useful by centering them around 0 by subtracting the mean. It is indicated by the symbol C:
=\alpha+\beta_1x_1^C+\beta_2x_2^C+\beta_3x_1^Cx_2^C)
Now the coefficient of x1 (so β1) shows the effect of x1 when x2 is at its mean. These effects are similar to the effects in a model without interaction. The advantages of centering are that the estimates of x1 and x2 give more information and that the standard errors are similar to those of a model without interaction.
Reduced models (showing only some variables) can be better than complete models (showing all variables). For a complete model E(y) = α + β1x1 + β2x2 + β3x3 + β4x1x2 + β5x1x3 + β6x2x3 , the reduced version is: E(y) = α + β1x1 + β2x2 + β3x3. The null hypothesis says that the models are identical: H0 : β4 = β5 = β6 = 0.
A comparison method is to subtract the complete model SSE (SSEc) from the reduced model SSE (SSEr). Because the reduced model is more limited, its SSE will always be bigger and be a less accurate estimate of reality. Another comparison method subtracts the different R2-values. The equations are:
/df_1}{SSE_c/df_2}=\frac{(R_c^2-R_r^2)/df_1}{(1-R_c^2)/df_2})
Df1 are the number of extra predictors in the complete model and df2 are the other degrees of freedom. A big difference in SSE or a big R2 means a bigger F and smaller P, so more evidence against H0.
The partial correlation is the strength of the association between y and the explanatory variable x1 while controlling for x2 :
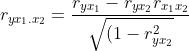(1-r_{x_1x_2}^2)}})
In the partial correlation ryx1.x2 , the variable on the right side of the dot is the control variable. A first order partial correlation has one control variable, a second order partial correlation has two. The characteristics are similar to regular correlations; the value is between -1 and 1 and the bigger it is, the stronger the association.
The partial correlation also has a squared version:

The squared partial correlation is the proportion of the variance in y that is explained by x1. The variance in y exists of a part explained by x1, a part explained by x2, and a part that is not explained by these variables. The combination of the parts explained by x1 and x2 is R2. Also when more variables are added, R2 is the part of the variance in y that is explained.
The standardized regression coefficient (β*1, β*2, etc) is the change in the mean of y for an added 1 standard deviation, measured in standard deviations instead of other units of measurement. The other explanatory variables are controlled. This compares whether an increase in x1 has a bigger effect on y than an increase in x2. The standardized regression coefficient is estimated by standardizing the regular coefficients:
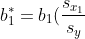)
In this, sy is the sample standard deviation of y and sx1 is the sample standard deviation of an explanatory variable. In SPSS and other software, the standardized regression coefficients are sometimes called BETA (beta weights). Just like the correlation, they indicate the strength of an association, but in a comparative way. When the value exceeds 1, the explanatory variables are highly correlated.
For a variable y the zy is the standardized version; the version expressed in the number of standard deviations. When zy = (y – ȳ) / sy, then its estimate is: ẑy = (ŷ – ȳ) / sy. The prediction equation estimates how far an observation falls from the mean, measured in standard deviations: