


- 3.1 Welke tabellen en grafieken worden gebruikt voor beschrijvende statistiek?
- 3.2 Hoe bereken je centrummaten (gemiddelde, mediaan en modus)?
- 3.3 Hoe geef je de spreiding van data weer?
- 3.4 Hoe kun je een distributie weergeven met kwartielen en andere op positie georiënteerde meetmaten?
- 3.5 Hoe heet statistiek met meerdere variabelen?
- 3.6 Hoe maak je in formules het verschil tussen de steekproef en de populatie duidelijk?
- TentamenTickets
3.1 Welke tabellen en grafieken worden gebruikt voor beschrijvende statistiek?
Beschrijvende statistiek dient om een overzicht te creëren van de data en deze samen te vatten. Er moet onderscheid gemaakt worden tussen kwantitatieve en categorische data. Bij deze typen data kunnen niet altijd dezelfde beschrijvende statistieken gebruikt worden.
Bij categorische data is het voor het overzicht het makkelijkst als de categorieën in een lijst staan met achter iedere categorie de frequentie (hoe vaak een waarde voorkomt). Om de categorieën beter met elkaar te kunnen vergelijken, worden vaak ook de relatieve frequenties weergegeven. De relatieve frequentie van een categorie geeft aan hoe vaak een subject binnen deze categorie valt, in vergelijking tot het geheel. Dit is te berekenen als percentage of als proportie. Het percentage is het totale aantal observaties binnen die categorie, gedeeld door het totale aantal observaties * 100. Er kunnen ook proporties berekend worden. Dat gaat op dezelfde manier, maar dan vermenigvuldig je niet met 100. De som van alle proporties moet uiteindelijk 1.00 zijn, en de som van alle percentages moet 100 zijn.
Frequenties zijn weer te geven met een frequentiedistributie. Een frequentiedistributie is een weergave van een lijst met alle mogelijke waarden van een variabele en het aantal observaties van elke waarde. Nog meer informatie wordt weergegeven in een relatieve frequentiedistributie, waarin ook de verhoudingen ten opzichte van het geheel worden getoond. Een voorbeeld hiervan is een relatieve frequentietabel.
Voorbeeld (relatieve) frequentietabel:
Geslacht | Frequentie | Proportie | Percentage |
Man | 150 | 0.43 | 43% |
Vrouw | 200 | 0.57 | 57% |
Totaal | 350 (=n) | 1.00 | 100% |
Naast tabellen wordt ook vaak gebruik gemaakt van meer visuele weergaven, zoals staafdiagrammen, taartdiagrammen, histogrammen en steelbladdiagrammen.
Een staafdiagram wordt gebruikt bij categorische variabelen en geeft per categorie een staaf weer. De staven zijn van elkaar gescheiden om aan te geven dat er geen sprake is van kwantitatieve variabelen.
Een taartdiagram wordt ook gebruikt bij categorische variabelen, elke categorie wordt gerepresenteerd door een stuk van de taart. Als de waarden echter dicht bij elkaar liggen, geven staafdiagrammen de verschillen duidelijker weer dan taartdiagrammen.
Voor kwantitatieve variabelen kunnen ook frequentietabellen en visuele weergaven gebruikt worden. Bij frequentietabellen worden dan niet de categorieën weergegeven maar de intervallen. Van elk interval kan de frequentie worden getoond, de proportie van het geheel en het percentage.
Een histogram is een grafiek waarin de frequentiedistributie van een kwantitatieve variabele wordt getoond. Bij weinig waarden kun je per waarde een staaf weergeven, bij veel waarden is het overzichtelijker om ze in te delen in intervallen.
Een steelbladdiagram (stem-and-leaf plot) geeft elke observatie weer met een steel en een blad; twee nummers die achter elkaar de observatie weergeven. Een steelbladdiagram is eigenlijk alleen nuttig als je weinig data snel wilt weergeven.
Wanneer visuele weergaven worden toegepast op een populatie spreekt men van een populatiedistributie; wanneer ze worden toegepast op een steekproef is dat een steekproefdistributie. De data kunnen worden weergegeven met een curve in een grafiek. Hoe groter de steekproef is en hoe meer data er beschikbaar is, hoe meer de grafiek lijkt op de curve van de gehele populatie.
De vorm van een grafiek geeft informatie over de verdeling (of distributie) van de data. De meest voorkomende vorm is de normale verdeling (ook wel normale distributie genoemd), een soort opstaande bel-vorm (zie de afbeelding). Deze is symmetrisch. Als de x-as de waarde van een variabele aangeeft, geeft de y-as de relatieve frequentie aan dat die waarde voorkomt. Het hoogste punt ligt in het midden, de middelste waarde komt dus het vaakst voor.

Een andere mogelijkheid is een grafiek in de vorm van een U. De waarden die dan het meest voorkomen, zijn de hoogste en laagste scores, wat polarisatie aangeeft.
De twee uitersten van de curve worden staarten genoemd (tails). Wanneer de ene staart langer is dan de andere, en de verdeling dus niet symmetrisch van vorm, is de verdeling linksscheef of rechtsscheef (skewed).
3.2 Hoe bereken je centrummaten (gemiddelde, mediaan en modus)?
Centrummaten geven een idee over waar het midden van de data ligt van een frequentiedistributie van een kwantitatieve variabele. De meest bekende is het gemiddelde: de som van de observaties gedeeld door de totale hoeveelheid observaties. Bijvoorbeeld: een variabele (y) heeft de waarden 34 (y1), 55 (y2) en 64 (y3). Het gemiddelde (ȳ) is (34 + 55 + 64)/3 = 51. Het gemiddelde spreek je uit als y-streepje.
De berekening van het gemiddelde ziet er in een formule als volgt uit: ȳ =  .
.
Het symbool ∑ is de Griekse hoofdletter sigma, dit betekent de som van hetgeen wat erachter staat. De kleine letter i betekent 1 tot n (de steekproefgrootte). Dus ∑ yi betekent y1 + y2 + … + yn (dit zijn dus alle observaties bij elkaar opgeteld).
Het gemiddelde kan alleen gebruikt worden bij kwantitatieve data en is zeer gevoelig voor uitschieters (outliers, ook wel uitbijters genoemd); bijzonder hoge of bijzonder lage waarden.
In geval van meerdere steekproeven (n1 en n2), kunnen er meerdere gemiddeldes worden berekend, te noteren als ȳ1 en ȳ2.
Een tweede centrummaat is de mediaan. De mediaan is de middelste observatie. Als een variabele bijvoorbeeld de waarden 1, 3, 5, 8 en 10 heeft, dan is de mediaan 5. Indien er een even aantal observaties is, bijvoorbeeld 1, 3, 8 en 10, dan is de mediaan (3 + 8)/2 = 5,5.
De mediaan heeft een aantal eigenschappen om rekening mee te houden:
Behalve kwantitatieve data is de mediaan ook geschikt voor categorische data met een ordinaal meetniveau, omdat er een zekere orde in de observaties nodig is voor de mediaan.
Bij volledige symmetrische data zouden de mediaan en het gemiddelde hetzelfde moeten zijn.
Bij een scheve verdeling ligt het gemiddelde, ten opzichte van de mediaan, dichter bij de staart.
De mediaan is niet gevoelig voor uitschieters. Dit is zowel iets positiefs als iets negatiefs. Het is positief, want als er één uitschieter in de data zit, geeft de mediaan geen vertekend beeld. Maar het is ook negatief, want variabelen kunnen van elkaar variëren met een enorme spreiding, terwijl de mediaan dan soms dezelfde middenwaarde aangeeft.
Het voordeel van de mediaan tegenover het gemiddelde is dat de mediaan een representatiever beeld geeft van de steekproef als er uitschieters zijn. De mediaan geeft meer informatie als de verdeling erg scheef is. Er zijn echter ook gevallen waarbij de mediaan minder handig is om te gebruiken. Als de data enkel binair is (alleen 0 of 1), dan is de mediaan de proportie van het aantal keer dat 1 geobserveerd wordt. Ook in andere gevallen waarin de data erg discreet is, geeft het gemiddelde een beter beeld van de data dan de mediaan.
Een derde maat is de modus: de waarde die het vaakst voorkomt. Deze is het nuttigst bij erg discrete variabelen, vooral bij categorische data, maar kan in principe voor alle typen gebruikt worden. De modus is ook nuttig bij bimodale distributies, waarbij de verdeling twee pieken heeft, bijvoorbeeld bij een opinieonderzoek waarin respondenten ofwel sterk tegen iets zijn ofwel sterk voor.
3.3 Hoe geef je de spreiding van data weer?
Naast het gebruik van centrummaten is het goed om ook de spreiding (ofwel variabiliteit) van de data te beschrijven. Je beschrijft dan de variabiliteit van de waardes van een variabele uit de data, bijvoorbeeld de spreiding van het inkomen van de respondenten. Er zijn verschillende manieren om de spreiding weer te geven.
Ten eerste kan het bereik (range) worden vermeld: het verschil tussen de laagste en de hoogste observatie. Bijvoorbeeld: de waarden 4, 10, 16 en 20. Het bereik is 20 – 4 = 16.
De meest gebruikte methode om de spreiding weer te geven, is echter de standaarddeviatie (s). Een deviatie in het algemeen is het verschil tussen een gemeten waarde (yi) en het gemiddelde van de steekproef (ȳ), ofwel (yi – ȳ). Elke observatie heeft zijn eigen deviatie. Deze kan zowel positief als negatief zijn. Hij is positief wanneer de observatie een hogere waarde heeft dan het gemiddelde, en negatief wanneer deze een lagere waarde heeft dan het gemiddelde. Behalve dat je dit voor iedere observatie apart kan doen, kan je ook de standaarddeviatie van een variabele berekenen, door de som te nemen van alle losse deviaties. Hierbij hoort de volgende formule:
Het bovenste gedeelte van de formule, namelijk ∑ (yi – ȳ)2 wordt som van de kwadraten (sum of squares) genoemd. Dit gedeelte is belangrijk, het kwadrateert de afzonderlijke deviaties van de observaties. Hoe groter de afzonderlijke deviaties, hoe groter de standaarddeviatie. De informatie die de standaarddeviatie geeft, is hoeveel een observatie typisch afwijkt van het gemiddelde, en dus hoe groot de spreiding van de data is. Als de standaarddeviatie 0 is, dan is er helemaal geen variabiliteit in de data.
wordt som van de kwadraten (sum of squares) genoemd. Dit gedeelte is belangrijk, het kwadrateert de afzonderlijke deviaties van de observaties. Hoe groter de afzonderlijke deviaties, hoe groter de standaarddeviatie. De informatie die de standaarddeviatie geeft, is hoeveel een observatie typisch afwijkt van het gemiddelde, en dus hoe groot de spreiding van de data is. Als de standaarddeviatie 0 is, dan is er helemaal geen variabiliteit in de data.
De variantie is:
s2 =
De variantie is het gemiddelde van de kwadraten van de deviaties. De standaarddeviatie wordt vaker gebruikt om de spreiding aan te geven dan de variantie.
Als er data beschikbaar is voor de gehele populatie, dan wordt bij het berekenen van de standaarddeviatie geen n-1 gebruikt maar de populatiegrootte.
Er is een vuistregels voor het interpreteren van s, deze regel heet de empirische regel:
Ten eerste ligt 68% van de data tussen ȳ – s en ȳ + s.
Ten tweede ligt 95% tussen de ȳ – 2s en ȳ + 2s.
Ten derde vallen vrijwel alle observaties tussen ȳ – 3s en ȳ + 3s.
Deze regel uit de praktijk is vooral bruikbaar bij distributies in de vorm van een bel. In een voorbeeld: stel ȳ = 3 en s = 1,5. Dan valt 68% tussen 1,5 en 4,5. Dan valt 95% van de observaties tussen 0 en 6. En vrijwel alle observaties liggen tussen de -1,5 en 7,5. In een visuele weergave ziet dit er als volgt uit:

Outliers hebben een groot effect op de standaarddeviatie.
3.4 Hoe kun je een distributie weergeven met kwartielen en andere op positie georiënteerde meetmaten?
Distributies kun je uitdrukken aan de hand van allerlei posities. Een manier om een distributie in te delen, is bijvoorbeeld in percentielen. Het pde percentiel is het punt waarbij p% van de observaties onder of op dat punt vallen en de rest van de observaties, namelijk (100-p)%, erboven. Let op, met percentiel wordt specifiek dat punt op de grafiek bedoeld, niet een deel van de grafiek.
Een andere manier om een distributie in te delen, is in vieren. Het 25e percentiel heet dan het eerste kwartiel (in het Engels lower quartile) en het 75e percentiel heet het derde kwartiel (in het Engels upper quartile). De helft van de data ligt hiertussen en wordt de interkwartielafstand genoemd (afgekort IQR). De mediaan verdeelt de IQR in tweeën. Het eerste kwartiel is de mediaan van de eerste helft en het derde kwartiel is de mediaan van de tweede helft. Het voordeel van de IQR tegenover het bereik en de standaarddeviatie is dat de IQR niet gevoelig is voor uitschieters.
Om een distributie weer te geven, kam de vijf-getallensamenvatting worden gebruikt: minimum, eerste kwartiel, mediaan, derde kwartiel en maximum. Deze vijf posities kun je tonen in een boxplot, een grafiek die aan de hand van deze vijf posities de spreiding weergeeft.
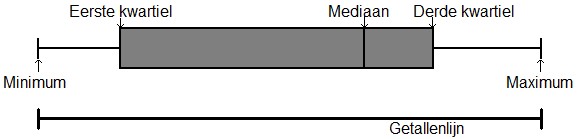
De lijnen die naar het minimum en maximum lopen, heten de whiskers. Als er extreme uitschieters zijn, worden ze aangeduid met een rondje buiten de whiskers. Een observatie wordt als uitschieter beschouwd wanneer deze zich meer dan 1,5 interkwartielafstand onder het eerste kwartiel of boven het derde kwartiel bevindt. In een boxplot zijn de uitschieters erg duidelijk te zien, dit is handig voor de onderzoeker omdat uitschieters een indicatie kunnen zijn dat er iets niet klopt of dat er nogmaals naar de onderzoeksmethoden moet worden gekeken.
Om twee of meerdere groepen te vergelijken voor een variabele, kunnen meerdere soorten grafieken worden gebruikt. Voorbeelden zijn een relatieve frequentiedistributietabel, histogram of twee boxplots naast elkaar.
Een andere positie is de z-score. Dit is het aantal standaarddeviaties dat een waarde afligt van het gemiddelde. De formule hiervoor is: z = (observatie – gemiddelde) / standaarddeviatie. In tegenstelling tot andere posities, geeft de z-score informatie over een afzonderlijke waarde.
3.5 Hoe heet statistiek met meerdere variabelen?
In statistiek wordt vaak de associatie tussen twee variabelen onderzocht; of de ene variabele invloed heeft op de andere variabele. Dit heet een bivariate analyse.
Meestal wordt het effect bestudeerd dat een verklarende variabele (ofwel onafhankelijke variabele) heeft op een responsvariabele (ofwel afhankelijke variabele). De uitkomst van de responsvariabele wordt uitgelegd door de verklarende variabele.
De invloed die een variabele heeft op een andere variabele, kan op verschillende manieren visueel worden weergegeven. Een kruistabel (contingency table) bestaat uit rijtjes met de uitkomsten van de combinatie van variabelen. Een puntgrafiek (scatterplot) is een grafiek met op de x-as de verklarende variabele en op de y-as de responsvariabele. Een puntgrafiek heeft voor elke uitkomst waarbij aan de twee variabelen wordt voldaan een puntje. De sterkte van de associatie wordt de correlatie genoemd. Met regressieanalyse kan worden voorspeld wat de waarde van y is bij een gegeven waarde x. Als er een associate is tussen variabelen, betekent dit echter niet per se dat er ook een causaal verband is. Er kan ook sprake zijn van meerdere variabelen, dan is multivariate analyse nodig.
3.6 Hoe maak je in formules het verschil tussen de steekproef en de populatie duidelijk?
Een belangrijk onderscheid is dat tussen de statistiek die enkel de steekproef beschrijft, en de parameter die de gehele populatie beschrijft. Griekse letters worden gebruikt voor de populatieparameters, Romeinse letters voor de steekproefstatistieken. Bij een steekproef is ȳ het gemiddelde en s de standaarddeviatie. Bij een populatie is μ het populatiegemiddelde en σ de standaarddeviatie van de populatie. Het gemiddelde en de standaarddeviatie van een steekproef kun je ook behandelen als variabelen. Bij een populatie kan dat niet, omdat er slechts een populatie is.
TentamenTickets
Als je moet kiezen om data weer te geven met een gemiddelde, mediaan of modus, bestudeer dan eerst de data en beoordeel hoe je deze zelf zou interpreteren. Als de waarden bijvoorbeeld verrassend hoog uitvallen, of als het achterliggende doel van een onderzoek is om aan te geven dat veel respondenten juist in het midden zitten, kies dan de centrummaat die dat het duidelijkst weergeeft.
De beste manier om statistiek te leren bedrijven, blijft oefenen! Zorg dat je een paar keer de centrummaten hebt berekend (gemiddelde, mediaan en modus).
Laat je niet afschrikken door formules. Als je formules moeilijk vindt, bijvoorbeeld die van de standaarddeviatie, schrijf dan voor jezelf in letters op wat de onderdelen van de formule zijn. De som van kwadraten bijvoorbeeld, ∑ (yi – ȳ)2, is de som van alle uitkomsten van de steekproef, min het gemiddelde, in kwadraat.
Het belang van de standaarddeviatie kan moeilijk overschat worden, deze komt vaak terug in de statistiek. Zorg dat je weet hoe je de standaarddeviatie moet berekenen en snapt welke informatie de standaarddeviatie geeft.

Access:
Public

Join WorldSupporter!
Join with a free account for more service, or become a member for full access to exclusives and extra support of WorldSupporter >>
Check more of topic:
Going abroad?
Study with summaries


Contributions: posts
Help other WorldSupporters with additions, improvements and tips

Spotlight: topics
Check the related and most recent topics and summaries:
Activities abroad, study fields and working areas:
WorldSupporter and development goals:
Institutions, jobs and organizations:

Check how to use summaries on WorldSupporter.org
Submenu: Summaries & Activities
Follow the author: Annemarie JoHo

Work for WorldSupporter

JoHo can really use your help! Check out the various student jobs here that match your studies, improve your competencies, strengthen your CV and contribute to a more tolerant world
Statistics
Add new contribution