
Startmagazine: Introduction to Statistics
Startmagazine: Introduction to Statistics
Introduction to Statistics: in short
- Statistics comprises the arithmetic procedures to organize, sum up and interpret information. By means of statistics you can note information in a compact manner.
- The aim of statistics is twofold: 1) organizing and summing up of information, in order to publish research results and 2) answering research questions, which are formed by the researcher beforehand.
Introduction to Statistics
This page presents an explanation of some fundamental concepts regarding statistics. In the connected pages you can find:
- A glossary of the most important terms generally associated with Introduction to statistics
- Selected contributions of other WorldSupporters regarding Introduction to statistics
- Practice questions for Introduction to statistics
- Tips, explanations and examples per topic when encountering, understanding and applying statistics (feel free to explore!)
- Updates of contributions by WorldSupporter Statistics
As a behavioral scientist, it is important to understand statistics. Research is namely conducted using empirical techniques, of which statistics is an essential part. When you understand which technique should be applied in which situation, you can use statistics correctly.
Basic terminology
Often, research is conducted to examine the association between variables. A variable is a characteristic or condition that is changeable, or has different values for different individuals, for example age. These are person variables. But, variables can also apply to characteristics of the surroundings, for example temperature. Here, they are called environmental variables. Variables are noted by means of letters, for example variable X and variable Y. There are different kinds of variables. An independent variable is a variable that is being manipulated by the researcher. It often comprises two or more conditions, to which participants are being exposed. The dependent variable is the variable that is being observed after manipulating the observed variable. It shows what the effect is of the different conditions of the independent variable. Often, a control group is used in an experiment. This group receives no treatment or a placebo to see if there is a difference between the experimental condition and the control group. Variables can also be subdivided into discrete and continuous variables. A discrete variable comprises different categories. For example, a class can consist of 18 or 19 children, but can not consist of 18.5 children. For a continuous variable, there are infinite numbers or values possible between two observed values. Think for example of length and weight.
Many variables that are being examined, are hypothetical constructs. Think for example of self-confidence. These constructs can not be measured directly. To measure these constructs, definitions of these constructs have to be formed that can be examined. For example, intelligence can be examined by using an IQ test. An operational definition describes how this construct should be examined. For example, hunger can be described as ‘the state in which someone is after not eating for at least 12 hours’. This is an example of an operational definition.
Research designs
Researchers can use four different research designs to test hypotheses:
Descriptive research: with descriptive research, the behavior, thoughts and feelings of a group of individuals are described. Developmental psychologists for example try to describe the behavior of children of different ages.
Correlational research: with correlational research, the association between variables is studied. With correlational studies, no statements can be made about cause-and-effect relationships.
Experimental research: in experimental studies, a variable (the independent variable) is manipulated to examine its possible effects on behavior (the dependent variable). If this is true (and all other assumptions are met), we can conclude that the independent variable causes these changes. The main feature of an experiment is the manipulation of the independent variable.
Quasi-experimental research: this type of design is used when researchers are, for whatever reason, not able to manipulate the variable. Think for example of gender and age. The researcher studies the effects of a variable of an event that happens naturally and can not be manipulated. Quasi-experiments do provide less certainty than real experiments.
The research process
The research process comprises seven steps:
Select a topic.
Demarcate and specify the topic. Study prior research with regard to your topic and specify the research question(s).
Set up a plan to answer the research question, and examine which research design is most appropriate for this.
Collect data to find an answer to your question.
Analyse the data. Look for patterns in your data.
Interpret the data; give meaning to your data.
Publish the results of your research, and inform others about the results.
The above steps are rarely clearly separated from each other: conducting research is an interactive process in which many steps are intermingled with each other. In addition, sometimes you have to go back to a prior step of the process.
Types of statistics
There are different types of statistics. Descriptive statistics is used to describe the data. We can calculate the mean, display the data in a graph or look for extreme scores. Inferential statistics refers to making inferences about the population, based on a certain sample. By means of inferential statistics, we try to answer answer this. When a measurement refers to the whole population, it is called a parameter. When a measure refers to the sample, it is called a statistic. Statistics are thus estimates of the parameter.
Basic symbols
In statistics it is important not to loose sight of the difference between the statistic that describes only the sample and the parameter that describes the entire population. Greek letters are used for the population parameters, Roman letters are used for the sample statistics. For a sample ȳ indicates the mean and s indicates the standard deviation. For a population μ indicates the population mean and σ the standard deviation of the population. The mean and the standard deviation can also be regarded as variables (for a population there is no mean or standard deviation because there is only one population).
Below, you see a table with some useful and frequently used symbols:
| Symbol | Symbol Name | Meaning / definition | Example |
|---|---|---|---|
| P(A) | probability function | probability of event A | P(A) = 0.5 |
| f (x) | probability density function (pdf) | P(a ≤ x ≤ b) = ∫ f (x) dx | |
| F(x) | cumulative distribution function (cdf) | F(x) = P(X≤ x) | |
| μ | population mean | mean of population values | μ = 10 |
| E(X) | expectation value | expected value of random variable X | E(X) = 10 |
| E(X | Y) | conditional expectation | expected value of random variable X given Y | E(X | Y=2) = 5 |
| var(X) | variance | variance of random variable X | var(X) = 4 |
| σ2 | variance | variance of population values | σ2 = 4 |
| std(X) | standard deviation | standard deviation of random variable X | std(X) = 2 |
| σX | standard deviation | standard deviation value of random variable X | σX = 2 |
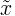 | median | middle value of random variable x | 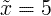 |
| ρX,Y | correlation | correlation of random variables X and Y | ρX,Y = 0.6 |
| ∑ | summation | summation - sum of all values in range of series | 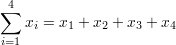 |
Measurement levels
Variables can be subdivided into four different measurement levels, which are summarized below from lowest to highest level of measurement:
Nominal: the simplest (lowest) measurement level is the nominal scale. For nominal variables, numbers only refer to categories. Measurement on the nominal scale categorize and label observations. The number 1 for example can be used for ‘men’ and the number 2 can be used for ‘women’. One can not calculate something with these numbers, because they are only labels.
Ordinal: an ordinal variable comprises a set of categories with an ordering. For example, you can order the participants of a singing competition of worst to best on the basis of the applause they received. However, we can not determine perfectly how much more applause one or the other singer received.
Interval: here, we do speak of ‘real’ number. Equal differences between number on this scale reflect equal differences in strength. However, with interval variables, there is no defined zero point. For example, you can not say a person has zero height. Because there is no zero level, we can not multiply or divide the numbers of an interval scaled variable.
Ratio: here, we do speak of a zero-level. Because of this, we are able to add, subtract, multiply and divide observations. Examples of ratio scaled variables are weight and reaction time.
| Levels of Measurement | ||||
| Ratio | Absolute zero | |||
| Interval | Distance is meaningful; no absolute zero | |||
| Ordinal | Atrributes can be ordered; distance not meaningful | |||
| Nominal | Atributes are only named; cannot be ordered | |||
Glossary for Introduction to Statistics


Practice Questions for Introduction to Statistics
 Practice Questions for Introduction to Statistics
Practice Questions for Introduction to Statistics
Questions
1. What is the difference between an independent and a dependent variable? Describe both terms.
2. Study both definitions of the term performance-motivation, as given below.
- Someone gets assigned the task to build a tower of matches. Performance-motivation refers to the number of attempts someone tries, before he or she quits.
- Performance-motivation is the ability to set yourself to do a certain performance.
Are these definitions conceptual or operational?
3. What does ‘correlational research’ mean?
4. A researcher wants to examine to what extent giftedness of children at secondary school coincides with behavioral problems in the class. What kind of research is suitable to examine this question?
5. What is the form of statistics called, that focuses on drawing conclusions?
6. Someone claims about a certain variable that the score of Elise is twice as large als the score of Adriaan. Which level of measurement should the variable at least have to be able to make certain claims?
7. In a study, the variable intelligence is measured as:
1 = IQ below 70
2 = IQ between 71 and 90
3 = IQ between 91 and 110
4 = IQ between 111 and 120
5 = IQ higher than 120
Which level of measurement does this variable hold?
8. In a study, the connection between gender, age and cognitive abilities is examined. Which of these variables can exclusively play a role as independent variable in psychological research?
Answers
1. What is the difference between an independent and a dependent variable? Describe both terms.
An independent variable is a variable that is being manipulated by the researcher. Often, this exists of two conditions to which the participants are exposed. The dependent variable is a variable that is observed, after the independent variable is manipulated.
2. Study both definitions of the term performance-motivation, as given below.
- Someone gets assigned the task to build a tower of matches. Performance-motivation refers to the number of attempts someone tries, before he or she quits.
- Performance-motivation is the ability to set yourself to do a certain performance.
Are these definitions conceptual or operational?
Definition I is operational.
Definition II is conceptual.
Definition II is conceptual.
3. What does ‘correlational research’ mean?
With this type of study, the association between variables is studied. With correlational studies, no claims can be made about cause-and-effect relationships.
4. A researcher wants to examine to what extent giftedness of children at secondary school coincides with behavioral problems in the class. What kind of research is suitable to examine this question?
Correlational research
5. What is the form of statistics called, that focuses on drawing conclusions?
Inferential statistics.
This method assumes that the independent variable has had a certain effect, if the difference between the means of the conditions is larger than expected based upon coincidence only. Therefore, we compare group means that we found with group means that we would have expected if there would only be some error variance. Unfortunately, this method does not provide certainty. Only a chance can be determined, which implies that the differences in group means are the result of error variance.
6. Someone claims about a certain variable that the score of Elise is twice as large als the score of Adriaan. Which level of measurement should the variable at least have to be able to make certain claims?
Ratio
7. In a study, the variable intelligence is measured as:
1 = IQ below 70
2 = IQ between 71 and 90
3 = IQ between 91 and 110
4 = IQ between 111 and 120
5 = IQ higher than 120
Which level of measurement does this variable hold?
Ordinal
8. In a study, the connection between gender, age and cognitive abilities is examined. Which of these variables can exclusively play a role as independent variable in psychological research?
Gender and age
Selected contributions for Introduction to Statistics
 Selected contributions for Introduction to Statistics
Selected contributions for Introduction to Statistics
Selected contributions of other WorldSupporters on the topic of Introduction to Statistics
Knowledge and assistance for Introduction to Statistics
Introduction to statistics
Glossary, practice questions, selected contributions
Related topics for encountering, understanding and applying statistics
Updates & About WorldSupporter Statistics
Take statistics to the next level!
Topics related to Introduction to Statistics
Statistics: Magazines for encountering Statistics
Statistics: Magazines for encountering Statistics
Knowledge and assistance for discovering, identifying, recognizing, observing and defining statistics.
Statistics: Magazines for understanding statistics
Statistics: Magazines for understanding statistics
Knowledge and assistance for classifying, illustrating, interpreting, demonstrating and discussing statistics.
Statistics: Magazines for applying statistics
Statistics: Magazines for applying statistics
Knowledge and assistance for choosing, modeling, organizing, planning and utilizing statistics.
Updates & About WorldSupporter Statistics
What can you do on a WorldSupporter Statistics Topic?
 What can you do on a WorldSupporter Statistics Topic?
What can you do on a WorldSupporter Statistics Topic?
- Understand statistics with knowledge and explanation about a topic of statistics
- Practice with questions and answers to test your statistical knowledge and skills
- Watch statistics practiced in real life with selected videos for extra clarification
- Study relevant terminology with glossaries of statistical topics
- Share your knowledge and experience and see other WorldSupporters' contributions about a topic of statistics
Updates of WorldSupporter Statistics
Updates of WorldSupporter Statistics
Latest news and updates of WorldSupporter Statistics

Add new contribution